
What Is Indexing? How Search Engines Store and Understand Web Pages

-
nimda
- June 9, 2026
Introduction
Many website owners focus on rankings, keywords, and backlinks, but one of the most important stages of search visibility happens long before a page can rank. That stage is indexing.
Before a search engine can show a webpage in search results, it must first discover the page, analyze its content, understand its purpose, and decide whether it deserves a place in its index. If a page is not indexed, it cannot appear in search results regardless of how well it is optimized.
Understanding indexing is essential because it acts as the bridge between crawling and ranking. A website may publish valuable content and follow SEO best practices, but if important pages are not indexed, they remain invisible to searchers.
This guide explains what indexing is, how it works, why it matters, what prevents pages from being indexed, and how website owners can improve their chances of index inclusion.
What Is Indexing?
Indexing is the process by which search engines analyze, organize, and store information from web pages after they have been crawled.
When a search engine discovers a page, it does not automatically make that page eligible for search results. Instead, it evaluates the page’s content, structure, relevance, and quality before deciding whether it should be added to its index.
The search index functions like a massive digital library. Rather than searching the entire internet whenever someone performs a query, search engines retrieve information from this index to deliver relevant results quickly.
In simple terms:
- Crawling discovers content
- Indexing stores and understands content
- Ranking determines where content appears in search results
Without indexing, ranking cannot occur.
Why Indexing Matters in SEO
Indexing is one of the most important foundations of search engine optimization.
Every SEO effort depends on search engines first including a page in their index. If a page is not indexed, it cannot generate impressions, clicks, or organic traffic.
Proper indexing allows search engines to:
- Understand page content
- Associate pages with relevant search queries
- Evaluate quality and relevance signals
- Determine search eligibility
- Deliver content to users when appropriate
Many website owners assume ranking problems are caused by poor SEO, when in reality the issue may begin at the indexing stage.
How Search Engines Index Web Pages
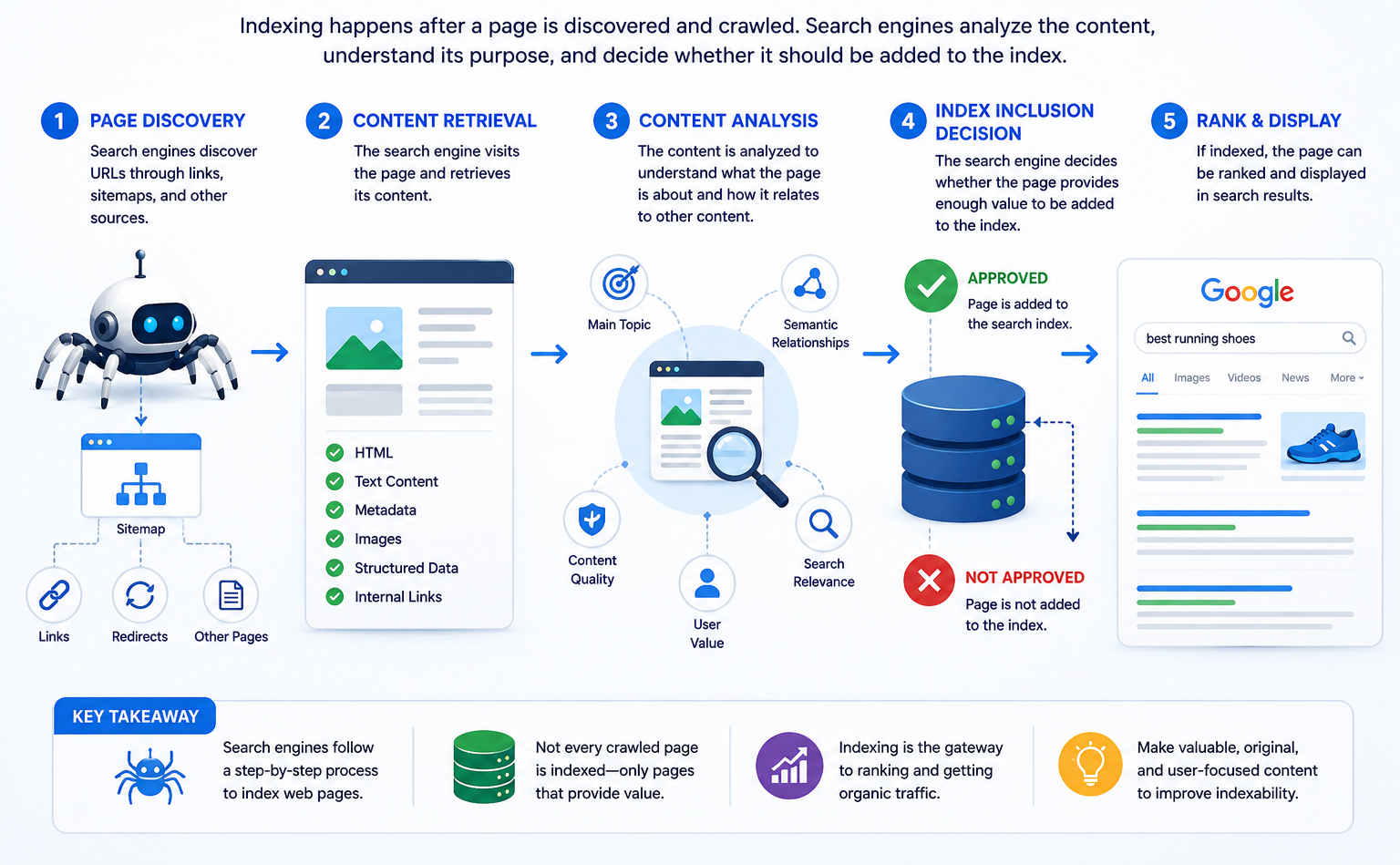
Indexing occurs after a page has been discovered and crawled.
Although search engines use sophisticated systems, the process generally follows several steps.
Page Discovery
Search engines first discover URLs through:
- Internal links
- External links
- XML sitemaps
- Redirects
- Previously indexed pages
Once discovered, the page enters a crawl queue.
Content Retrieval
The search engine visits the page and downloads its content, including:
- HTML
- Text content
- Metadata
- Images
- Structured data
- Internal links
Content Analysis
The page is then analyzed to determine:
- Main topic
- Content quality
- Semantic relationships
- Search relevance
- User value
At this stage, search engines attempt to understand what the page is about and how it relates to other content on the web.
Index Inclusion Decision
Not every crawled page is indexed.
Search engines evaluate whether a page provides enough value to justify inclusion in the index.
If approved, the page becomes eligible to appear in search results.
How Search Engines Decide Whether to Index a Page
A common misconception is that every crawled page gets indexed. In reality, indexing is a selective process.
Search engines aim to provide users with the most useful and relevant information possible. As a result, they evaluate pages before deciding whether to store them in the index.
Factors that may influence indexing decisions include:
Originality
Pages that offer unique information are more likely to be indexed than pages that largely duplicate existing content.
Content Quality
Search engines look for content that demonstrates expertise, usefulness, and completeness.
User Value
Pages that solve a problem, answer a question, or provide meaningful information tend to offer stronger indexing signals.
Duplication
When multiple pages contain substantially similar content, search engines may choose to index only one version.
Content Depth
Thin or incomplete pages often struggle to earn index inclusion.
Indexing is therefore not only a technical process but also a quality assessment process.
The Difference Between Crawling, Indexing, and Ranking
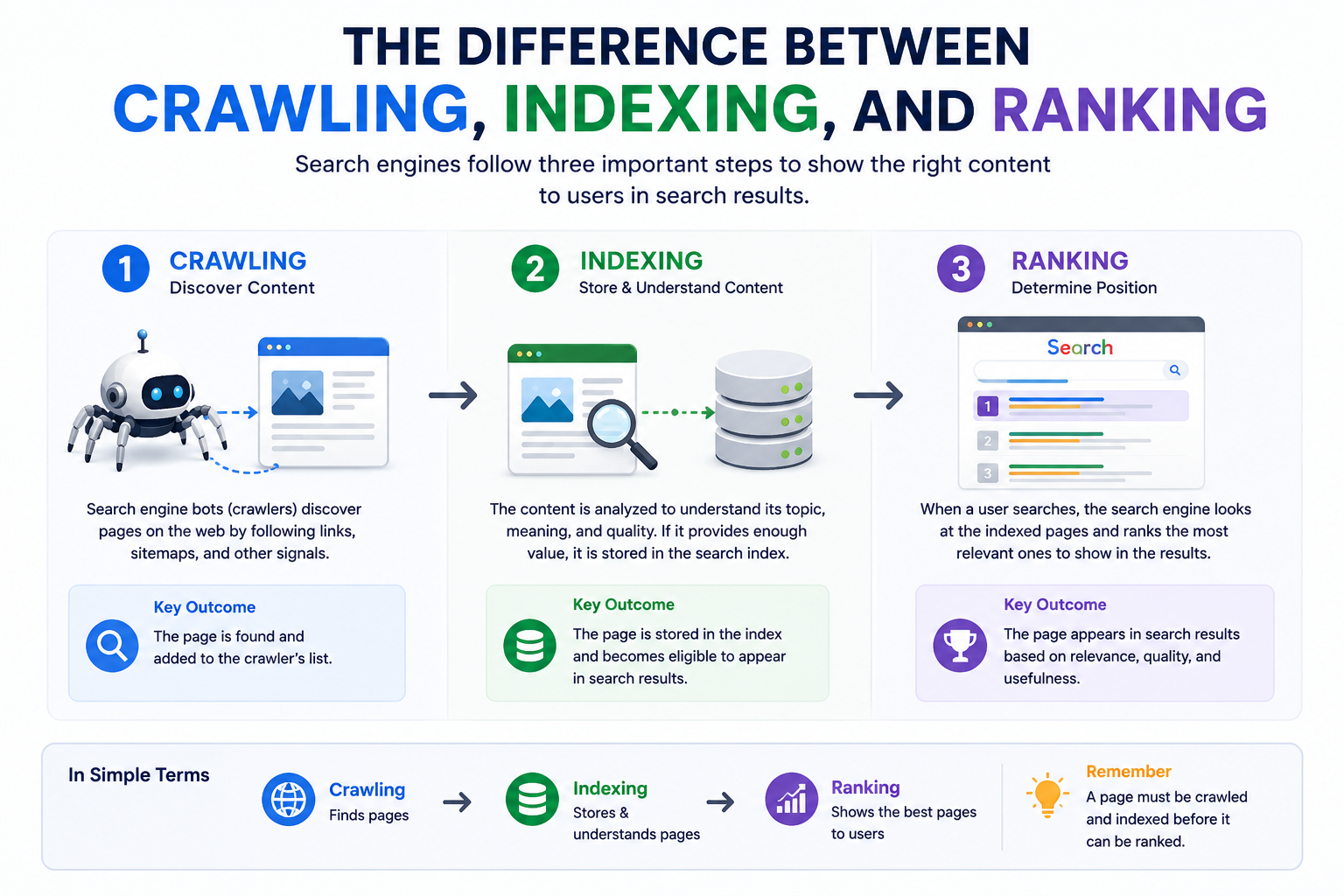
A page can be crawled without being indexed, but it cannot rank unless it has first been indexed.
What Information Do Search Engines Store During Indexing?
When a page enters the index, search engines store far more than just the URL.
Information may include:
Page Content
The text and information contained on the page.
Topics and Semantic Relationships
The subjects and concepts associated with the content.
Entities
People, organizations, products, places, and other identifiable concepts mentioned within the content.
Internal Link Relationships
Connections between pages that help establish site structure and topic relevance.
Structured Data
Additional context provided through schema markup.
Media Information
Images, videos, and supporting metadata.
Canonical Signals
Information that helps search engines determine the preferred version of similar pages.
Common Indexing Statuses Explained
Website owners often encounter indexing reports that describe the current state of a page.
Indexed
The page is stored in the search engine index and may appear in search results.
Crawled – Currently Not Indexed
The page has been crawled but was not selected for indexing.
Discovered – Currently Not Indexed
The search engine knows the page exists but has not crawled it yet.
Excluded by Noindex
The page contains instructions preventing indexing.
Duplicate Page
Search engines have identified another version of the content and selected that version for indexing instead.
Why Some Pages Are Not Indexed
Not all pages qualify for index inclusion.
Common reasons include:
Duplicate Content
Multiple versions of similar content can reduce the need for indexing every page.
Thin Content
Pages with little useful information may not provide enough value for inclusion.
Technical Restrictions
Noindex directives, authentication barriers, and other restrictions can prevent indexing.
Poor Internal Linking
Pages with few internal links may be harder for search engines to evaluate and prioritize.
Rendering Problems
If search engines cannot properly access or understand content, indexing may be affected.
How Canonical Tags Affect Indexing
When multiple URLs contain similar or identical content, search engines must determine which version should be indexed.
Canonical tags help indicate the preferred version of a page.
This allows indexing signals to be consolidated and reduces confusion caused by duplicate content variations.
Proper canonicalization supports cleaner indexing and helps search engines understand which URL should represent the content in search results.
What Is Index Bloat?
Index bloat occurs when large numbers of low-value pages become eligible for indexing.
Common examples include:
- Thin tag pages
- Filter URLs
- Duplicate content variations
- Internal search result pages
When too many low-quality pages compete for indexing attention, search engines may spend resources evaluating content that provides little value to users.
Maintaining a clean and focused index helps search engines prioritize a website’s most important content.
Real-World Examples of Indexing Decisions
Example: A Page That May Not Be Indexed
A website publishes a short article containing information already available on hundreds of other websites.
Although the page can be crawled successfully, search engines may decide it offers little unique value and choose not to index it.
Example: A Page Likely to Be Indexed
A comprehensive guide provides original insights, useful explanations, and strong organization.
Because it offers meaningful value to users, it is more likely to be included in the search index.
Best Practices for Improving Indexability
Website owners can improve their chances of indexing by:
- Creating original content
- Providing clear user value
- Strengthening internal linking
- Maintaining a logical site structure
- Using XML sitemaps
- Managing duplicate content carefully
- Implementing canonical tags correctly
- Ensuring pages remain technically accessible
- Updating important content when necessary
Although indexing decisions ultimately belong to search engines, these practices can significantly improve indexability.
Common Myths About Indexing
Every Crawled Page Gets Indexed
Crawling and indexing are separate processes.
XML Sitemaps Guarantee Indexing
Sitemaps assist discovery but do not guarantee inclusion.
More Pages Mean Better SEO
Large numbers of low-quality pages can create indexing challenges.
Indexing Happens Instantly
Search engines require time to evaluate and process content.
Rankings Depend Only on Keywords
A page must first be indexed before ranking factors can matter.
Final Thoughts
Many website owners focus primarily on rankings, yet search visibility begins much earlier in the search engine process. Before a page can compete for rankings, it must first earn inclusion in the search engine index.
Indexing is the process that allows search engines to store, understand, and evaluate web pages. It serves as the critical bridge between crawling and ranking, helping determine which content becomes eligible to appear in search results.
By creating valuable content, maintaining a clear site structure, managing duplication carefully, and ensuring pages are accessible to search engines, website owners can improve their chances of successful index inclusion and long-term organic visibility.